
The 5 worst bugs I've seen on production - #1 the N+1 problem
Published 10 months ago

This happened when we least expected it: an alert warned that one endpoint’s response time had jumped from about one second to nearly ten. At first we thought it was a traffic spike. Then we opened the DB panel and saw the pattern.
What is it?
The N+1 problem is when code runs one query to fetch a list, and then runs one more query for each item in that list, leading to N+1 total queries. It often shows up after a “quick” join or when related data is lazily loaded. See: ORM N+1 select problem (Baeldung).
Problem
The extra JOIN ran per fetched row. For 100 parent rows, we now did ~100 more lookups (plus work per child). Classic N+1, just hidden inside a “harmless” refactor. Caches didn’t help because we were still doing lots of tiny queries.
Impact
The monitoring graph looked like a heart rate diagram—spikes one after another during a single request. Unlike the neat, “chunked” examples you see online, our tool drew them as many thin lines: dozens of tiny queries packed so tightly it was hard to read the shape. The pattern was still there, loud and clear. With a realistic dataset, the endpoint climbed to around 10 seconds in production.
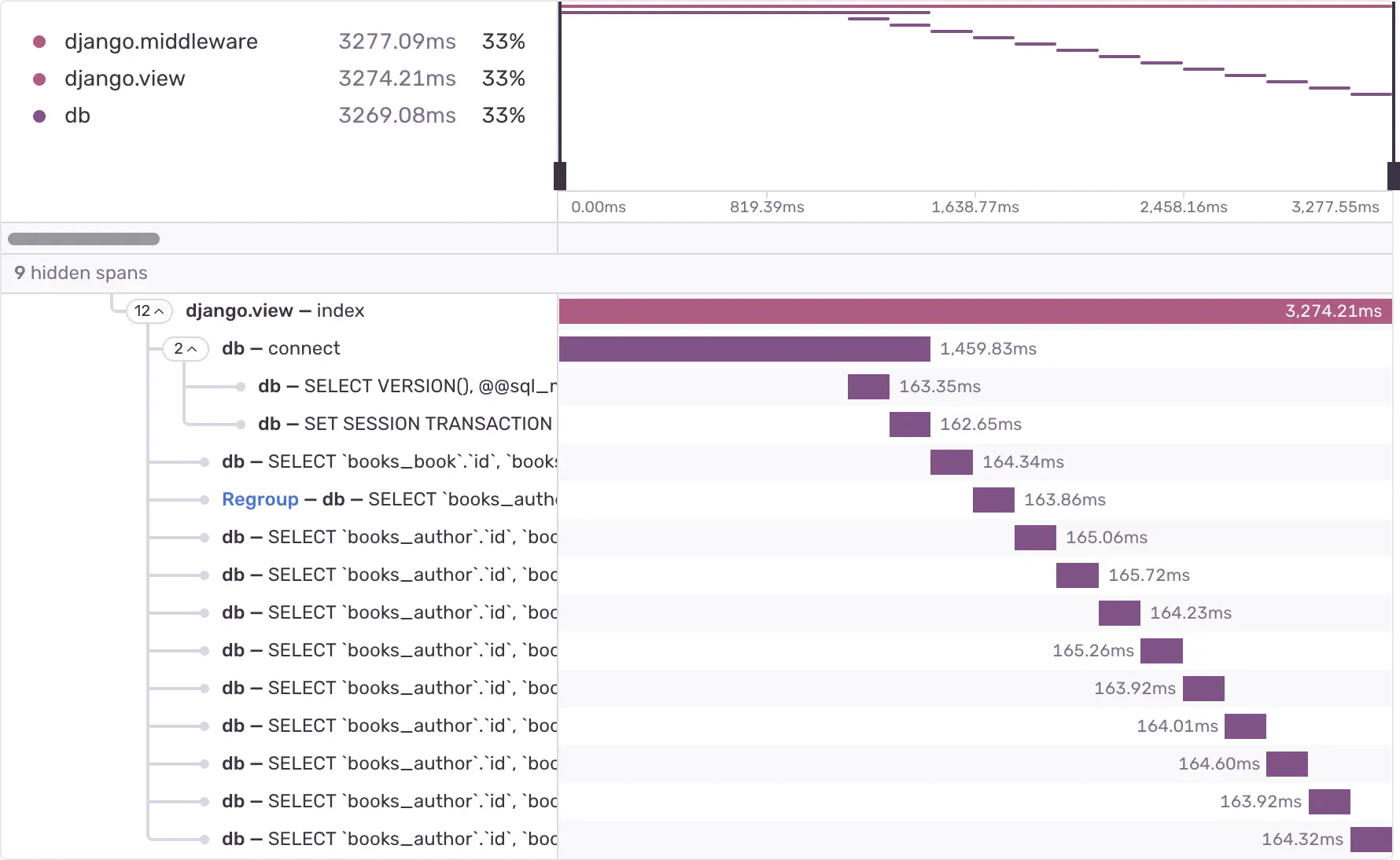
From Sentry’s docs: https://docs.sentry.io/product/issues/issue-details/performance-issues/n-one-queries/. Their example shows clear chunky groups. In our case the monitor rendered thin lines—tens to hundreds of tiny queries per request—so imagine this graph compressed into finer strips until the request hit ~10s.
Solution
The fix lived in code: fetch related data in one go (do the JOIN once) or use eager loading/prefetch where the ORM supports it. This is something you need to recognize while coding—if it reaches production, you already shipped the problem. It’s also hard to catch with local tests unless you use production‑like volumes.
Lesson learned: N+1 is a coding‑time pitfall. Know the pattern, avoid per‑row queries, and when in doubt prefer eager loading/prefetch. Local tests often miss it unless the dataset is realistic.